I never really thought about it enough to actually sit down and figure it out at the time, but, conveniently enough, last week's installment left us fully equipped to address this type of question. We learned then that rounding errors can be thought of in terms of continuous distributions, and that when those errors are added, the resulting distribution can be described in terms of the total combined variance and standard deviation. For the rounding errors for the yardage of football plays, we can think of this distribution as a one-yard wide distribution centered on the whole number.
In other words, let's say Barry Sanders rushes for 2 yards. Whether he really gained 4 1/2 feet, or 7 1/2 feet, or anywhere in between, the NFL is just going to call it 6 feet. That 2-yard gain could fall anywhere on the continuous spectrum from 1.5 yards to 2.5 yards, and when we see a 2-yard gain recorded in the data, we have no idea where in that spectrum the gain falls. That is a continuous distribution, and the standard deviation for the rounding error of this play is .289 yards.
Before we go on, I'd like to highlight some of the assumptions we are making here when we choose a continuous distribution that is one-yard wide. One, we are assuming every gain is properly rounded to the nearest whole yard. In reality, maybe the ref spots the ball 4.4 yards from the line of scrimmage and the scorer eyeballs that and sees it as a 5 yard gain, or the ball is spotted for a 4.6 yard gain and the scorer marks it as a 4 yard gain. Because of this, when you see a two yard gain, the distribution of possible gains will actually be a bit wider than 1 yard, and it won't be continuous, but slope downward toward the ends. However, we'll ignore that so that we can mathematically describe the situation. Another thing being ignored is the distribution of gains on all plays in the NFL, or for a given player. If more runs go for 2 yards than 1 yard, and more runs go for 3 runs than 2 yards (I am making this up; I have no idea if this is how rushing gains are distributed in the NFL or not), then when you see a 2-yard gain, it is more likely to be rounded down than rounded up. That won't give us a continuous distribution either. But, for our purposes, we are going to assume we know nothing about how gains are distributed (hey, I actually don't know that!) and act under the assumption that there is no reason to believe any number in the spectrum from 1.5 yards to 2.5 yards is any more likely than another.
Now that that is out of the way, let's continue. The SD for the rounding error of each play is .289 yards. Now, let's say Barry Sanders rushes again, this time for no gain. His total yardage is 2 yards, and the standard deviation for the rounding error is sqrt(.289^2+.289^2) = .408 yards. This is just after 2 runs, and the error is already close to half a yard and growing quickly. Is this going to be a problem as the number of plays adds up? It's still just third down, so Barry has one more play before Detroit has to punt, so let's keep going.
For his third run, Barry rushes for 87 yards. Now his total for 3 plays is 89 yards, with a standard deviation of sqrt(.289^2+.289^2+.289^2) = .500 yards. At one play, the error started out at .289. With the next play, it rose to .408, for an additional .120 yards of error (heh, look at those rounding errors popping up again). On the third run, the error rose by another .092 yards. As you can see, the effect of each additional play diminishes, so maybe it won't be much of a problem after all.
If you read last week's article, you'll remember that the rounding errors were a relatively large issue when PAs were small, but that the error shrunk substantially when PAs became high. The error in yardage we're talking about here won't ever shrink (the only reason the error shrank when we were talking about wOBA was that we divided the error by PA, and the PA term started growing a lot faster than the error term), but its growth will slow down considerably.
Instead of just 3 rushes, let's say Barry Sanders carries the ball 300 times in a season. The standard deviation of the rounding error is sqrt(300*.289^2) = 5 yards. While it only took 3 plays for the error to reach a SD of .5 yards, it took 300 plays to get up to 5 yards. If we look at Barry Sanders whole career of 3000 or so rushes, the SD of the rounding error only gets up to about 16 yards. If some QB goes all Brett Favre on us and keeps slinging the ball every which way until he racks up 6,000 completions (you only need to look at completions for QBs, since the error around the 0 yards for an incompletion can be considered to be 0, spotting errors aside), the SD on the error would still be well under 25 yards. That's pretty reassuring to the way the NFL adds things up.
There still is some imprecision from the rounding, though, so what about the questions introduced in the first paragraph? If a back is credited with 990 yards rushing, what are the chances he was above 1000 without rounding? To answer this, we need to know a little more about the distribution of possible errors. Specifically, we need to know what kind of shape the distribution takes.
If we're lucky, the distribution will be normal, because then the math is simple (or rather, there are plenty of tools readily available that do the math for us, which is a really simple way to "do" math). Remember that we started off with a uniform distribution when we only have one play, which looks like this:

That is clearly not a normal distribution, but the math is still simple with a uniform distribution. When we add a second play, then the distribution for the combined error becomes triangular:

The tip looks a bit rounded in that graph because of how Excel decided to handle things and because I am too lazy to fire up R, but it isn't. It's just straight up triangular. Again, clearly not normal, but still simple enough.
When you add in a third play, then the math for the actual distribution starts to get complicated. It is basically a piecemeal series of polynomial functions that each describe one portion of the distribution. To describe the distribution for combined rounding error for 3 plays, you need 3 different functions, and each play you add means you need to add another function to the mix. What's more, to get the distribution for 3 plays, you need to know the distribution for 2 plays. To derive the distribution for 300 plays, you have to derive the previous 299 distributions as well*, which involves thousands of individual functions. Let's just say, we really don't want to have to use the actual distributions, so we'd better hope that there is a simpler distribution that is a good approximation.
Lo and behold, there is. Here is the actual distribution for 3 plays, along with the normal approximation of the distribution using the same standard deviation:

And here is the actual CDF compared to the normal approximation (click for a larger image, since it is hard to see the difference between the two lines on this graph),
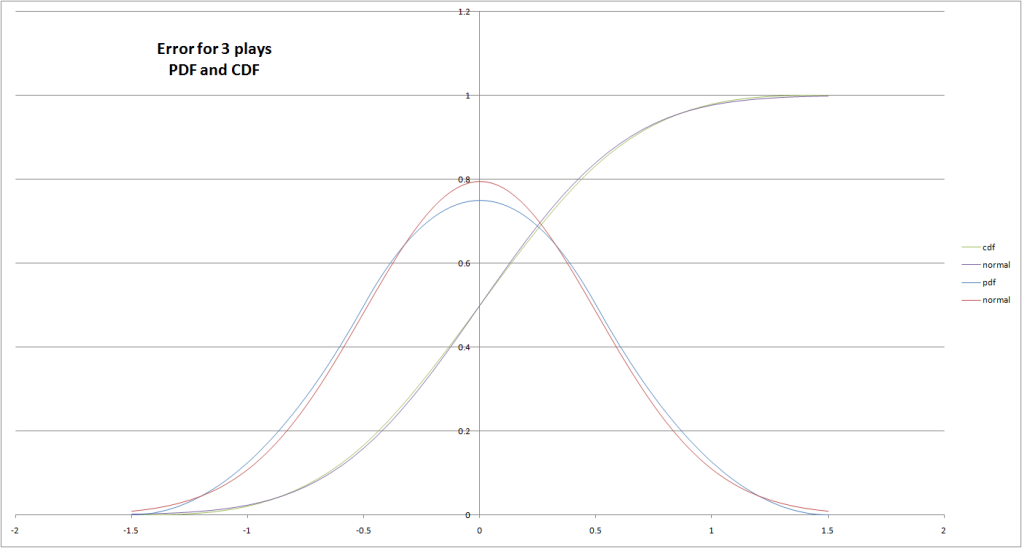
Once you get to 3 plays, the distribution of possible rounding errors starts looking very much like a normal distribution (sweet beans beluga, as my friend would say)**. Which is good, because it's probably what we would have used whether it was a good fit or not, because no one here wants to spend 8 months doing the real math.
Back to the question, how likely is it that the 990 yard rusher got rounded out of his 1000 yard season? It depends on how many carries he had, but if we know he had 300 carries, and we know 1000 yards would require a rounding error of at least 10 yards, then that is a magnitued of 2 SDs for the rounding error. That means there's only about a 2.3% chance that his precise total of 1000+ got rounded down to 990 (rule of thumb is that 95% of a normal distribution is within 2 SDs of the mean, and half of the outcomes outside of the 95% are on the low end of the distribution, leaving about two-and-a-half percent two SD above the mean). If he rushes for 999 yards (poor fellow), then there's a 42% chance he really got rounded down from 1000+. As you can see, it can make a pretty big difference over few yards, but the chances of the error being much more than that diminish pretty quickly. The same thing goes for passing yards for QBs or receivers; most of the rounding errors for a season will be within a few yards. For a 10 year career, the SD for the distribution of errors will be about 3 times as high as for a single year, so adjust accordingly if you want to look at careers (10 yards would be less than 1 SD, so that kind of error would be a lot more common at the career level).
How about if we want to know something like, what are the odds that, if we could have measured their gains with perfect precision, we would discover that Marshall Faulk actually out-gained Jim Brown? According to Pro-Football-Reference, Jim Brown rushed for 12,312 yards in 2359 carries. Marshall Faulk rushed for 12,279 yards in 2836 carries. Those numbers of carries give the distributions of rounding errors SDs of 15.4 and 14.0, respectively. We want to know how much of Faulk's distribution of possible precise totals is greater than some portion of Brown's distribution. To do this, we can subtract their individual distributions. This gives us a new distribution, which is also normal, with a mean equal to the difference between their credited yardages (33 yards) and a SD equal to the square root of the sum of the variances of their individual distributions (20.8 yards). Plug those into your calculator or spreadsheet or table of values of choice to find the odds that x < 0 (meaning the difference Brown minus Faulk is actually negative, which would indicate Faulk gained more yards than Brown), and you end up with 5.6%. Not a lot, but it's there.
Or, how about another close pairing on the all-time rushing list, Corey Dillon and O.J. Simpson? They are just 5 yards apart over a combined 5000 carries. Repeat the math, and there is a 40% chance precise measurements would give Simpson the higher total and that rounding errors pushed him below Dillon.
Really, none of this is very significant. Basically, I just dragged you through 2,000 words to tell you there's not much difference between 11,241 yards and 11,236 yards over a full career. It's common sense, really. Still, I think it's interesting to have an idea of just how little difference it makes that the NFL is so imprecise with its yardage measurements (though, to be clear, this says nothing about the additional errors that would be involved with imprecisions like eyeballing the gain and rounding it incorrectly, or the official mis-spotting the ball, or anything like that; nonetheless, you get the idea that those things are probably not that big a deal here either). At the very least, it's good to know that the rounding errors overwhelmingly fall within the range of what you would look at and say there's really not much difference there.
*I don't know if there is actually a simpler way to derive the actual distributions, just that the only way I do know how to do it is a huge pain in the ass
**Relating to last week's article on rounding errors of wOBA, deriving the actual distributions for the rounding error of wOBA is more complicated since each of the 6 terms in the wOBA formula carries a different weight, so I didn't actually go through with deriving them past 2 terms to compare to a normal distribution. Simulated results for rounding errors of wOBA do appear to fit just as well to a normal distribution, though, so you can probably use the SDs from that article as if they describe a normal distribution as well.***
***If you thought this footnote was going to be about my friend who says "sweet beans beluga", well, that's just because I didn't have a better place to insert a footnote about deriving the distribution for wOBA, so I stuck it in at a largely irrelevant spot. I can tell you, though, that she spells it balooga when she uses it as an interjection, which is kind of interesting (at least compared to footnotes about deriving distributions for possible rounding errors) Continue Reading...